etags guide
etags简介
etags是一个索引源代码的工具,经过一段时间的使用,发现某些行为与手册上的描述不一致,还有一些地方的描述比较模糊。通过阅读源代码,发现了一些不曾出现在手册上的规则,也明白了一些原来感觉很模糊的地方。
etags分为两个部分:可执行程序etags,由 lib-src/etags.c 编译而来,用于扫描源代码,生成TAGS文件;etags.el是Emacs的一部分,它使用TAGS文件来完成定位、查找等各项工作。
生成TAGS文件
生成TAGS文件的方式很简单,比如给Emacs源代码生成TAGS文件
etags src/*.[hc] lib-src/*.[hc] lib/*.[hc] \
lisp/*.el lisp/*/*.el
这条命令在当前目录生成一个TAGS文件。
另外一种复杂的方式是生成多个TAGS文件,然后使用 --include 生成一个主文件,如
for dir in src lib-src lib; do \ pushed $dir; \ etags *.[hc] -o TAGS.sub; \ INCLUDES="$INCLUDES --include $PWD/TAGS.sub"; \ popd \ done for dir in lisp lisp/*; do \ pushd $dir; \ etags *.[hc] -o TAGS.sub; \ INCLUDES="$INCLUDES --include $PWD/TAGS.sub"; \ popd \ done etags -o TAGS $INCLUDES
按照手册的说法,使用这两种方式生成的TAGS文件的效果应该是一样的。然而在实际使用中,我发现它们的行为有较大差别,至少对于部分命令如此,根据我的感受,推荐使用第一种方式生成TAGS文件,第二种方式的体验较差。
首先是 find-tag 命令,使用第一种方式生成的TAGS文件能够更快定位,而第二种方式则需要更多次地用 C-u M-. 查找。
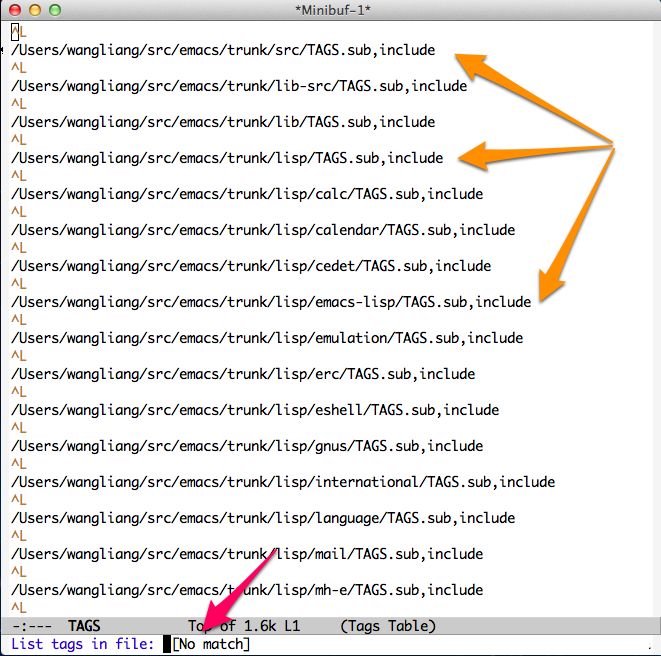
其次是 list-tags 命令,第一种方式可以正常工作,而第二种则完全不能工作,因为 list-tags 只查找在主TAGS文件里引用的那些文件,然而这个TAGS里只有include指令,没有引用任何源文件,因此甚至没法完成输入(我个人认为这是个bug),如下图:
为此,我写了一个新的命令 wl-list-tags-recursively ,解决 list-tag 不能处理由第二种方式生成的TAGS文件的问题。
(defun wl-tags-complete-tags-table-file-recursively (string predicate what) (save-excursion ;; If we need to ask for the tag table, allow that. (tags-completion-table) (let ((enable-recursive-minibuffers t)) (visit-tags-table-buffer)) (let ((first-time t) (files nil) beg) (while (visit-tags-table-buffer (not first-time)) (setq first-time nil) (goto-char (point-min)) (while (search-forward "\f\n" nil t) (setq beg (point)) (end-of-line) (skip-chars-backward "^," beg) (or (looking-at "include$") (push (convert-standard-filename (buffer-substring beg (1- (point)))) files)))) (setq files (nreverse files)) (if (eq what t) (all-completions string files predicate) (try-completion string files predicate))))) (defun wl-list-tags-recursively (file &optional _next-match) (interactive (list (completing-read "List tags in file: " 'wl-tags-complete-tags-table-file-recursively nil t nil))) (with-output-to-temp-buffer "*Tags List*" (princ "Tags in file `") (tags-with-face 'highlight (princ file)) (princ "':\n\n") (save-excursion (let ((first-time t) (gotany nil)) (while (visit-tags-table-buffer (not first-time)) (setq first-time nil) (if (funcall list-tags-function file) (setq gotany t))) (or gotany (error "File %s not in current tags tables" file))))) (with-current-buffer "*Tags List*" (require 'apropos) (with-no-warnings (apropos-mode)) (setq buffer-read-only t)))
使用TAGS文件
在Emacs里运行 M-x visit-tags-table RET ,然后输入TAGS文件路径即可。Emacs将这个文件放在一个buffer里面,并将major mode设置为 tags-table-mode 。在使用过程中,我们并不会直接使用这个buffer,而是通过一系列命令(比如 find-tag )间接使用它。
如果我们希望切换到另一个项目的TAGS文件,比如从Emacs切换到gcc,那么只需要再次调用 M-x visit-tags-table 并读入gcc相关的TAGS文件即可。需要注意的是,在第二次(以及之后)调用 visit-tags-table 的时候,会被询问:
Keep current list of tags tables also? (y or n)
这时需要回答 n 。之后Emacs会显示一条信息:
Starting a new list of tags tables
这时我们再使用任何etags命令,就只操作在gcc的TAGS文件上,Emacs的TAGS文件不会参与任何操作。如果想切换回Emacs的TAGS文件,只需调用 select-tags-table ,然后按照提示在相应TAGS文件上按 t 键即可。
那我们如果回答 y 会如何呢?在这种情况下,Emacs的TAGS文件和gcc的TAGS文件会同时参与etags命令。具体的影响可能有以下几种:
- tag数量增大,使得etags命令执行时间变长,响应迟钝;
- 如果两个TAGS文件里面有类似或相同的tag,则会严重影响使用体验;
因此,如果没有特殊的需求,最好不要合并不同项目的TAGS文件。
理解了TAGS文件、文件集合和集合的集合这三个概念,就可以根据自己需要,选
择回答 y 还是 n 。
- TAGS文件(
tags-file-name) - 初始值为用户创建的TAGS文件,如:"/home/liang/src/gcc/4.6.1/TAGS"。如果是用上述第二种方式创建的,在使用过程中tags-file-name的值可能会发生改变,它指向当前正在访问的TAGS文件。
- 文件集合(
tags-table-list) - 在回答 “Keep current list of tags tables also?” 时选择
y而合并了不同项目的TAGS文件而形成的集合,如:("/home/liang/project/emacs/trunk/TAGS" "/home/liang/src/gcc/4.6.1/TAGS") - 集合的集合(
tags-table-set-list) - 在回答 “Keep current list of tags tables also?” 时选择
n,而将之前的文件集合搁置,重新组建新的文件集合,这些文件的集合放在一起,就是集合的集合。从数据结构上来说,它就是tags-table-list可能取值的集合。如: (("/home/liang/project/emacs/trunk/TAGS" "/home/liang/src/gcc/4.6.1/TAGS") ("/home/liang/project/go/go/src/TAGS") ("/home/liang/src/gcc/4.6.1/TAGS"))
TAGS文件格式
TAGS文件不一定非要用etags程序生成,如果理解了它的文件格式,自己手写一个,照样能用,或者另外写个程序生成也可以。具体的格式描述参见源代码下的 etc/ETAGS.EBNF 文件。这里面有两个概念非常重要,即:explicit tag name和implicit tag name。etags程序会尽量使用implicit tag name,以减小TAGS文件的大小。所以我们在生成TAGS文件的时候,也应该尽量遵守这个规则,毕竟文件越小,响应越快。
implicit tag name的例子如下:
find_base_value ^?998,33275
explicit tag name的例子如下:
static char *reg_seen;^?reg_seen^A1175,38518
其中 ^? 和 ^A 是分隔符,分别对应字符 \177 和 \001 。后面两个数字分别为行号和行首字符位置。
判断是否可以使用implicit tag name的规则如下(摘自etags.c):
* make_tag creates tags with "implicit tag names" (unnamed tags) * if the following are all true, assuming NONAM=" \f\t\n\r()=,;": * 1. NAME does not contain any of the characters in NONAM; * 2. LINESTART contains name as either a rightmost, or rightmost but * one character, substring; * 3. the character, if any, immediately before NAME in LINESTART must * be a character in NONAM; * 4. the character, if any, immediately after NAME in LINESTART must * also be a character in NONAM.
由于 reg_seen 左边的字符为 * ,不属于 NONAM ,不符合生成implicit tag name的规则,所以必须生成explicit tag name,即之后重复出现的 reg_seen 部分。
索引etags不认识的语言
etags默认支持多种编程语言或者文档结构,在这种情况下,etags能够根据上述规则尽量使用implicit tag name。对于etags不支持的语言,我们可以使用 --regex 选项来指导etags生成TAGS文件,这时就要我们自己注意,在能够使用implicit tag name的情况下尽量使用,以减小文件大小。当然,生成更多的explicit tag name并不会产生任何正确性的问题。
下面的例子是用来索引go源程序的:
$ find . -name "*.go" | \
etags --language=none \
--regex='/type[ \t]+[^ \t]+[ \t]/' \
--regex='/func[ \t]+[^( \t]+[( \t]/' \
--regex='/func[ \t]+([ \t]*[^( \t]*[ \t]+\*?\([^) \t]+\)[ \t]*)[ \t]*\([^( \t]+\)[( \t]/\1.\2/' -
前面两个regex产生implicit tag name,最后一个regex生成explicit tag name,它生成的tag line如下:
func (url *URL) IsAbs(^?URL.IsAbs^A611,16231
也就是说,对于有receiver的函数,我们使用explicit tag name来进行更精确地定位,即通过 M-x find-tag RET URL.IsAbs RET 定位该函数的定义位置。
让find-tag首先定位当前buffer的tag
find-tag 定位tag受到很多因素的影响,有时候希望它能首先定位到当前
buffer的tag,但是它却跳到其它地方去了。如
http://debbugs.gnu.org/cgi/bugreport.cgi?bug=2544 描述的 static 函数
是一个例子,另外就是为不同体系结构或者操作系统实现接口时使用相同的名字。
如果我们注意到这种情况,那么只是操作上麻烦一点,倒还好说;如果没注意到,
那么可能完全读错了代码,我在读Android Dalvik garbage collection的实现时
就吃到了苦头。
为了解决这个问题,我对 find-tag 做了一点小小的改进,使其首先定位当前
buffer的tag,这样就不会造成困惑。
方法很简单,首先从 etags.el 从复制出三个函数: find-tag 、
find-tag-noselect 、以及 find-tag-in-order ,然后把他们重新命名为
wl-etags-find-tag 、 wl-etags-find-tag-noselect 和
wl-etags-find-tag-in-order ,并修改相应的调用点。最后把
wl-etags-find-tag-in-order 修改为下面的样子:
(defun wl-etags-get-from-buffer-file-name () (let ((marker (ring-ref find-tag-marker-ring 0))) (with-current-buffer (marker-buffer marker) buffer-file-name))) (defun wl-etags-goto-file (file) (let (beg) (while (and (search-forward "\f\n" nil t) (progn (setq beg (point)) (end-of-line) (skip-chars-backward "^," beg) (or (looking-at "include$") (not (string-equal file (expand-file-name (convert-standard-filename (buffer-substring beg (1- (point))))))))))) (if (eobp) nil t))) ;;; prefer tag in the same buffer as source buffer (defun wl-etags-find-tag-in-order (pattern search-forward-func order next-line-after-failure-p matching first-search) "Internal tag-finding function. PATTERN is a string to pass to arg SEARCH-FORWARD-FUNC, and to any member of the function list ORDER. If ORDER is nil, use saved state to continue a previous search. Arg NEXT-LINE-AFTER-FAILURE-P is non-nil if after a failed match, point should be moved to the next line. Arg MATCHING is a string, an English `-ing' word, to be used in an error message." ;; Algorithm is as follows: ;; For each qualifier-func in ORDER, go to beginning of tags file, and ;; perform inner loop: for each naive match for PATTERN found using ;; SEARCH-FORWARD-FUNC, qualify the naive match using qualifier-func. If ;; it qualifies, go to the specified line in the specified source file ;; and return. Qualified matches are remembered to avoid repetition. ;; State is saved so that the loop can be continued. (let (file ;name of file containing tag tag-info ;where to find the tag in FILE (first-table t) (tag-order order) (match-marker (make-marker)) goto-func (case-fold-search (if (memq tags-case-fold-search '(nil t)) tags-case-fold-search case-fold-search)) ) (save-excursion (if first-search ;; This is the start of a search for a fresh tag. ;; Clear the list of tags matched by the previous search. ;; find-tag-noselect has already put us in the first tags table ;; buffer before we got called. (setq tag-lines-already-matched nil) ;; Continuing to search for the tag specified last time. ;; tag-lines-already-matched lists locations matched in previous ;; calls so we don't visit the same tag twice if it matches twice ;; during two passes with different qualification predicates. ;; Switch to the current tags table buffer. (visit-tags-table-buffer 'same)) ;; Get a qualified match. (catch 'qualified-match-found ;; Iterate over the list of tags tables. (while (or first-table (visit-tags-table-buffer t)) (and first-search first-table ;; Start at beginning of tags file. (goto-char (point-min))) ;; Iterate over the list of ordering predicates. (while order ;; Only give one chance to tags in the from buffer here. ;; They can be found later. (when (and first-search first-table) (let ((file (wl-etags-get-from-buffer-file-name))) (when file (let* ((file-beg-pos (progn (wl-etags-goto-file file) (beginning-of-line) (point))) (file-end-pos (progn (search-forward "\f\n" nil t) (point)))) (goto-char file-beg-pos) (while (funcall search-forward-func pattern file-end-pos t) ;; Naive match found. Qualify the match. (and (funcall (car order) pattern) ;; Make sure it is not a previous qualified match. (not (member (set-marker match-marker (point-at-bol)) tag-lines-already-matched)) (throw 'qualified-match-found nil)) (if next-line-after-failure-p (forward-line 1))) ;; Nothing found. Restart from the beginning. (goto-char (point-min)))))) (while (funcall search-forward-func pattern nil t) ;; Naive match found. Qualify the match. (and (funcall (car order) pattern) ;; Make sure it is not a previous qualified match. (not (member (set-marker match-marker (point-at-bol)) tag-lines-already-matched)) (throw 'qualified-match-found nil)) (if next-line-after-failure-p (forward-line 1))) ;; Try the next flavor of match. (setq order (cdr order)) (goto-char (point-min))) (setq first-table nil) (setq order tag-order)) ;; We throw out on match, so only get here if there were no matches. ;; Clear out the markers we use to avoid duplicate matches so they ;; don't slow down editing and are immediately available for GC. (while tag-lines-already-matched (set-marker (car tag-lines-already-matched) nil nil) (setq tag-lines-already-matched (cdr tag-lines-already-matched))) (set-marker match-marker nil nil) (error "No %stags %s %s" (if first-search "" "more ") matching pattern)) ;; Found a tag; extract location info. (beginning-of-line) (setq tag-lines-already-matched (cons match-marker tag-lines-already-matched)) ;; Expand the filename, using the tags table buffer's default-directory. ;; We should be able to search for file-name backwards in file-of-tag: ;; the beginning-of-line is ok except when positioned on a "file-name" tag. (setq file (expand-file-name (if (memq (car order) '(tag-exact-file-name-match-p tag-file-name-match-p tag-partial-file-name-match-p)) (save-excursion (forward-line 1) (file-of-tag)) (file-of-tag))) tag-info (funcall snarf-tag-function)) ;; Get the local value in the tags table buffer before switching buffers. (setq goto-func goto-tag-location-function) (tag-find-file-of-tag-noselect file) (widen) (push-mark) (funcall goto-func tag-info) ;; Return the buffer where the tag was found. (current-buffer))))
从实现上来说,并非完美的方案,有值得商榷的地方;从使用上来说,完美解决 了我目前碰到的问题。:-)
集成etags与anything
list-tags 可以列出一个文件里的所有tag,所以我想是否可以把这个功能和anything集成起来,实现类似anything+imenu的功能。通常来讲,anything+etags能够比anything+imenu获得更多的candidates。具体实现如下:
(defun wl-list-tags (file) (with-current-buffer (get-file-buffer tags-file-name) (goto-char (point-min)) (when (wl-etags-goto-file file) (beginning-of-line) (let (tags) (forward-line 1) (while (not (or (eobp) (looking-at "\f"))) (add-to-list 'tags (cons (car (save-excursion (funcall snarf-tag-function t))) (save-excursion (funcall snarf-tag-function nil)))) (forward-line 1)) tags)))) (defun wl-anything-c-etags-in-current-buffer () (when (buffer-file-name) (let ((file (buffer-file-name)) (first-time t) tags tmp) (while (visit-tags-table-buffer (not first-time)) (setq first-time nil) (setq tmp (wl-list-tags file)) (when tmp (setq tags (append tmp tags)))) tags))) (defvar wl-anything-c-source-etags-in-current-buffer '((name . "Tags") (candidates . (lambda () (when (or tags-file-name tags-table-list) (with-current-buffer anything-current-buffer (wl-anything-c-etags-in-current-buffer))))) (action . (("Find tag" . (lambda (tag-info) (etags-goto-tag-location tag-info))))) (persistent-action . (("Find tag" . (lambda (tag-info) (etags-goto-tag-location tag-info))))) (delayed))) (defun wl-anything-etags-in-currect-buffer () (interactive) (anything 'wl-anything-c-source-etags-in-current-buffer nil nil nil nil "*anything etags for buffer*"))
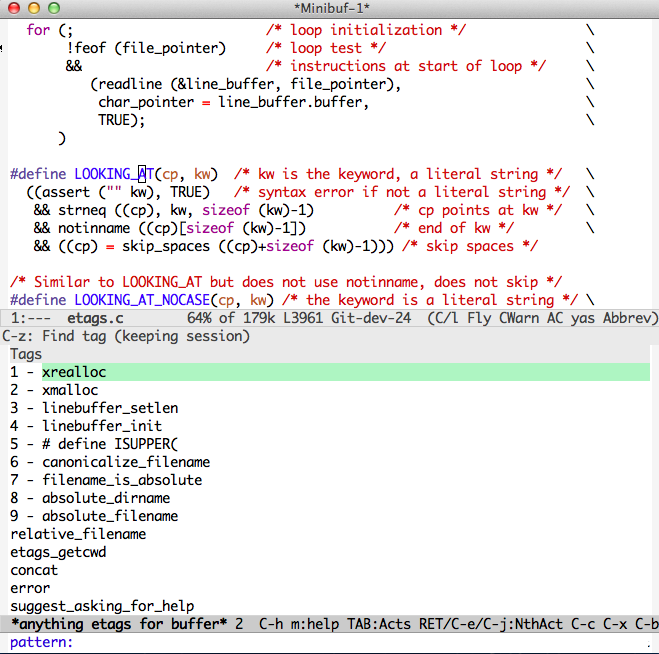
调用命令 wl-anything-etags-in-currect-buffer ,就可以列出当前buffer里面的所有tag,供选择定位。效果如图:
而 wl-anything-c-source-etags-in-current-buffer 作为一个symbol可以和其它source symbol组合起来使用,如:
(setq wl-anything-sources
(append anything-for-files-prefered-list
'(anything-c-source-emacs-process
anything-c-source-imenu
wl-anything-c-source-etags-in-current-buffer)))
(defun wl-anything ()
(interactive)
(anything wl-anything-sources))
其实anything默认已经集成了etags,只不过用法不一样,它显示TAGS文件里面的所有tag供选择,但是要求当前buffer对应的文件必须被TAGS文件索引,否则提示创建TAGS文件。
如果觉得传统的使用方式—— M-. 加 C-u M-. ——不爽,可以使用 tags-apropos 列出所有匹配正则表达式的tag,如果想限定到完全匹配的symbol,可以使用如下 wl-etags-apropos-symbol 命令:
(eval-after-load 'etags '(progn (defun wl-etags-apropos-symbol (tagname) (interactive (find-tag-interactive "Locate tag: ")) (tags-apropos (concat "\\_<" tagname "\\_>")))))
LLVM源码定位
开始学习一个新项目的时候,我都会为其创建一个TAGS文件,便于源代码定位,LLVM也不例外。
find . -iname "*.h" -or -iname "*.cpp" | etags -
find . -iname "*.td" | grep -v '^\./\(test/\|lib/Target/[^A]\)' | \
etags --language=none \
--regex='/\(defm?\|\(multi\)?class\)[ \t]+\([^ \t:<]+\)/\3/' \
-a -
除了C++程序之外,我还给LLVM TableGen的td文件也建立了索引,这样在学习td时也可以方便快捷地在 class 和 def 之间跳转,对 defm 和 multiclass 也做了有限的支持。
给go项目生成TAGS文件
此处的go项目特指包含go开发工具和程序库的代码,获取方式参见这里。
go项目包含多种编程语言写成的代码,如C,汇编,go等等,甚至包括C和go的混合体(文件后缀名为goc)。其中的C也不是标准的C,而是被称为Plan 9 C,其中会影响到etags的就是它使用unicode中的middle dot作为symbol名字的一部分,如 runtime·makechan_c 。它实际是一个函数名,感觉上runtime像是一个名字空间。
让etags认识middle dot的方法很简单,只需修改 emacs/lib-src/etags.c ,在 mitk 指向的字符串最后加上它就可以了。如下:
*midtk = "ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz$0123456789·";
在Emacs里输入middle dot的方法是: C-x 8 RET MIDDLE DOT RET 。或者直接从某个源文件里面复制。
然后重新编译
$ cd emacs/lib-src/ $ make etags
现在,就可以使用如下脚本给go项目生成TAGS文件了。
#!/usr/bin/env bash SRC_DIR=$1 if [ ! -e "$SRC_DIR/src/all.bash" ] then echo "\`$SRC_DIR' is not top directory of go source code" exit 1 fi pushd "$SRC_DIR" find src -name "*.go" | \ etags --language=none \ --regex='/type[ \t]+[^ \t]+[ \t]/' \ --regex='/func[ \t]+[^( \t]+[( \t]/' \ --regex='/func[ \t]+([ \t]*[^( \t]*[ \t]+\*?\([^) \t]+\)[ \t]*)[ \t]*\([^( \t]+\)[( \t]/\1.\2/' - find src -name "*.[hc]" | etags -a - find src -name "*.goc" | etags --language=c -a - find src -name "*.s" | etags -a --language=none \ --regex='/TEXT [^(]+/' - find include -name "*.h" | etags -a - popd
学习心得
etags.c和etags.el两个文件,断断续续看了近半年。开始的时候,一头雾水,看哪都不懂,一天天坚持下来,突然有一天开窍了,然后每天一个小模块,看到最后,竟然也明白个大概。有时想想,Emacs真得给了我很多,它
- 让我养成了读手册的习惯;
- 带我进入了Lisp的神奇世界;
- 使我能够持续改善工作流程;
- 甚至“强迫”我阅读它的实现代码!